
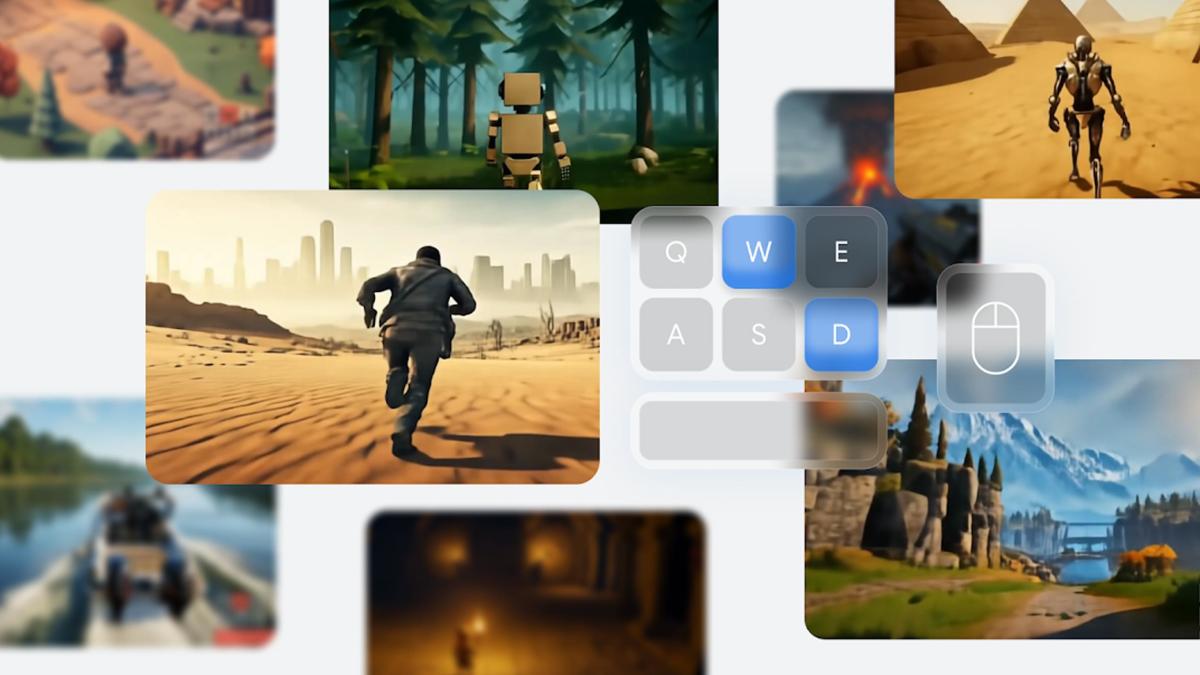
World models – artificial intelligence algorithms that can generate a simulated environment in real time – represent one of the most impressive applications of machine learning. There has been a lot of movement in the field over the past year, and to that end, Google announced DeepMind Genius 2 Wednesday. Where its predecessor was limited to generating 2D worlds, the new model can create 3D ones and sustain them for a significantly longer period.
Genie 2 is not a game engine; instead, it is a diffusion model that generates images as the player (a human or another AI agent) moves through the world that the software is simulating. As it generates frames, Genie 2 can infer ideas about the environment, giving it the ability to model water, smoke, and physical effects, although some of these interactions can be very playful. Furthermore, the model is not limited to playing scenes from a third-person perspective, but can also handle first-person and isometric viewpoints. All you need to get started is a single image, provided by Google Image 3 model or a picture of something in the real world.
Introducing Genie 2: our AI model that can create an infinite variety of playable 3D worlds, all from a single image. 🖼️
These types of large-scale foundation world models could allow future agents to be trained and evaluated in an infinite number of virtual environments. →… pic.twitter.com/qHCT6jqb1W
— Google DeepMind (@GoogleDeepMind) December 4, 2024
In particular, Genie 2 can remember parts of a simulated scene even after they have left the player’s field of vision, and can accurately reconstruct those elements once they become visible again. This is in contrast to other similar global models Oasiswho, at least in the version shown to the public by Decart in October, struggled to remember the layout of the Minecraft levels it was generating in real time.
However, there are also limits to what Genie 2 can do in this regard. DeepMind says the model can generate “coherent” worlds for up to 60 seconds, while most of the examples the company shared Wednesday last much less time; in this case, most videos are 10 to 20 seconds long. Additionally, artifacts are introduced and image quality softens as Genie 2 takes longer to maintain the illusion of a coherent world.
DeepMind provided no details on how it trained Genie 2 other than saying it was based “on a large-scale video dataset.” Don’t expect DeepMind to release Genie 2 to the public anytime soon, either. For now, the company sees the model primarily as a tool to train and evaluate other AI agents, including its own SIMA algorithmand something that artists and designers could use to quickly prototype and test ideas. In the future, DeepMind suggests that world models like Genie 2 will likely play an important role on the road to general artificial intelligence.
“Training more general embodied agents has traditionally been hampered by the availability of sufficiently rich and diverse training environments,” DeepMind said. “As we show, Genie 2 could allow future agents to be trained and evaluated in an unlimited curriculum of new worlds.”



